
안녕하세요. 데이터사이언스팀에서 데이터 분석 업무를 하고 있는 셀린이라고 합니다~
플랫폼 간 상품 매칭 알고리즘을 개발하는 연구 목적의 프로젝트를 4개월 동안 진행하였습니다.
해당 게시글을 통해 배경, 목표, 진행 과정, 결과, 향후 계획 그리고 저의 소감에 대해 공유드리고자 합니다.
배경
이 알고리즘 개발하면 뭐가 좋은데? 무슨 의도로 해당 과제를 제안하게 되었는지?
상품 매칭 알고리즘은 다양한 판매 도메인에서 활용될 수 있습니다. (E-Commerce 등)
아래 배경을 이해하시는 것을 돕기 위해 예시는 홈쇼핑 상품으로 하였습니다.
1. '수작업'매칭의 '자동화'로 인한 업무 효율 증대를 기대
홈쇼핑 채널을 넘겨보시다가 '어? 이 상품이 여기서도 파네?!', '그때 이 상품 봤던 것 같은데 여긴 구성이 좀 다르네.'와 같은 생각을 한 번쯤은 다들 해보셨다고 생각합니다. 아래의 예시 상품같이 여러 플랫폼(채널)에서 판매가 진행되는 상품을 '공유 상품'이라고 부릅니다. (ex. 하이뮨)
또, 다른 예시로 한 개의 플랫폼(채널)에서만 판매하는 '단독상품'이 있습니다. 'GS 단독', '오직 GS에서만' 등의 문구를 언제가 보신 적이 있으실 겁니다. (ex. 펌브러쉬, 크림)
해당 개념은 모든 유통 판매 도메인에 적용이 됩니다.

공유 상품들에 대해서는 타 플랫폼과 비교하여 구성, 가격 및 혜택 등에 대해 차별점을 두어야 하는 것이 중요하고,
단독 상품들에 대해서는 타 플랫폼에서 비슷한 상품을 판매하는지에 대한 현황을 먼저 빠르게 파악하는 것이 중요하다고 생각합니다.
이런 상황과 트렌드를 확인하기 위해 MD와 관련 실무자들은 타 플랫폼(채널)의 상품을 지속적으로 모니터링하고 있습니다.
다른 플랫폼(채널)에서도 팔고 있나? 팔면 어떻게 다르게 팔고 있나?
하지만, 같은 상품이더라도 상품명이 플랫폼(채널) 별로 제각각이기 때문에 동일한 상품인지 유사한 상품인지 한눈에 파악하기가 힘들고, 타 플랫폼(채널) 판매 상품 현황과 자사 상품들을 비교하는 작업을 수작업으로 모두 확인하는 것에는 적지 않은 어려움이 있습니다.
매칭 알고리즘을 개발하게 된다면 위 작업들을 자동화하면서 업무를 더 효율적으로 할 수 있을 거라 생각하였습니다.
2. 플랫폼(채널) 별 상품 포트폴리오 비교 및 전략방향 마련
매칭 알고리즘을 개발하여 상품들이 매칭 된다면 자사의 상품 중 타 플랫폼(채널)과 겹치는 상품이 얼마나 되는지,
경쟁력이 있는 단독 상품이 얼마나 되는지 등을 파악 가능할 것이라고 생각하였습니다.
거시적인 관점에서 자사를 중심으로 타 플랫폼과의 상품 포트폴리오를 한눈에 확인하는 것을 통해,
상품 판매의 전략 방향을 세우는 것에 도움이 될 수 있을 것이라 기대하였습니다.
아래의 벤다이어그램 구조로 상품군별 단독 상품 및 공유 상품의 %를 볼 수 있다면 상품 기획 관점에서 의미 있겠다는 생각을 하였습니다.

과제를 기획하면서 업무 효율을 증대하고 상품 포트폴리오를 파악하는 것에 활용이 될 수 있겠다는 생각도 했지만,
이 알고리즘이 자사의 상품과 타사의 상품을 데이터적으로 연결해줄 수 역할로서 분석의 범위를 더 넓힐 수 있을 거라는 생각도 하였습니다.
목표
그래서 명확히 나온 목표는 뭔데? 딱 정리하자면?
- 상품 매칭 알고리즘 개발 및 학술적 관점에서의 방법론 개선점 연구
- 타 플랫폼(채널) 상품 매칭을 통해 내/외부 상품의 포트폴리오 분석 및 상품 소싱 전략 방안 마련에 도움
- 방송 트렌드에 대한 신속한 인지 및 편성 전략의 질적 수준을 제고
진행 과정
어떤 데이터를 썼는지? 무슨 알고리즘을 개발했는지?
3년 5개월의 유사한 도메인에 있는 상품 정보 데이터 모두를 사용하였습니다. (총 1,417,459행)
자사 내부에서 관리하는 상품 체계 데이터도 추가로 사용하여 최대한 많은 정보를 활용하고자 하였습니다. (총 532,446행)
매칭에 중점적으로 사용된 변수는 '상품명'입니다. 기본적인 전처리를 한 뒤에 토큰화와 워드 임베딩 과정을 수행하였습니다.
많은 Tokenizer 중 사용한 데이터셋의 성능 및 결과 관점에서 최적인 Tokenizer를 선택하기 위해 여러 번의 테스트 과정을 거쳤습니다.
OOV(Out-of-Vocabulary) 문제에 민감도가 낮고 상품명 데이터의 패턴에 알맞은 확률 기반의 SoyNLP를 사용하였습니다.
비슷한 이유로 Word-Embedding도 Word2Vec가 아닌 FastText를 고려하였고,
Cosine Similarity에서는 보다 향상된 유사도 결과를 확보하기 위해 임베딩 시 추가로 Smooth Inverse Frequency를 적용하였습니다.
Jaccard Similarity에서는 계산 처리 속도를 향상시키기 위해 Word Set의 차원을 축소하는 방법론들을 추가로 적용하기도 하였습니다.
계산된 유사도에 대해 성능 측정을 시도해보는 것에서 많은 고민을 하였습니다.
동일 상품 여부를 파악하는 것에 도움을 줄 수 있는 자사 특정 코드를 이용하여 '매칭 유무(YN)'에 대한 변수를 생성하였고,
AUROC Score를 기준으로 0.9371 ~ 0.941의 성능을 확인할 수 있었습니다. (상품군별 차이가 있음)

유사도 계산의 결과에서 '매칭이 되지 않아야 할 상품이 유사도가 높게 나오는 경우'가 발생하는 것을 확인하였고,
가격, 브랜드, 세부 카테고리 정보들을 이용한 페널티 적용을 적용하여 해당 오류들에 대해 보완하는 작업도 수행하였습니다.
단순 상품명만으로는 구별해 낼 수 없었던 상품을 아래와 같은 페널티 도입을 통해 보다 정확한 결과를 도출할 수 있었습니다.

결과
개발된 최종 알고리즘은 무엇인지? 특정 상품을 매칭 했을 때 결과는 어떻게 나오는지?
기존 상품과 동일하거나 유사한 상품을 찾아주는 최종 상품 매칭 알고리즘은 아래와 같습니다.
- Cosine Similarity with Smooth Inverse Frequency
- Jaccard Similarity with Minhash
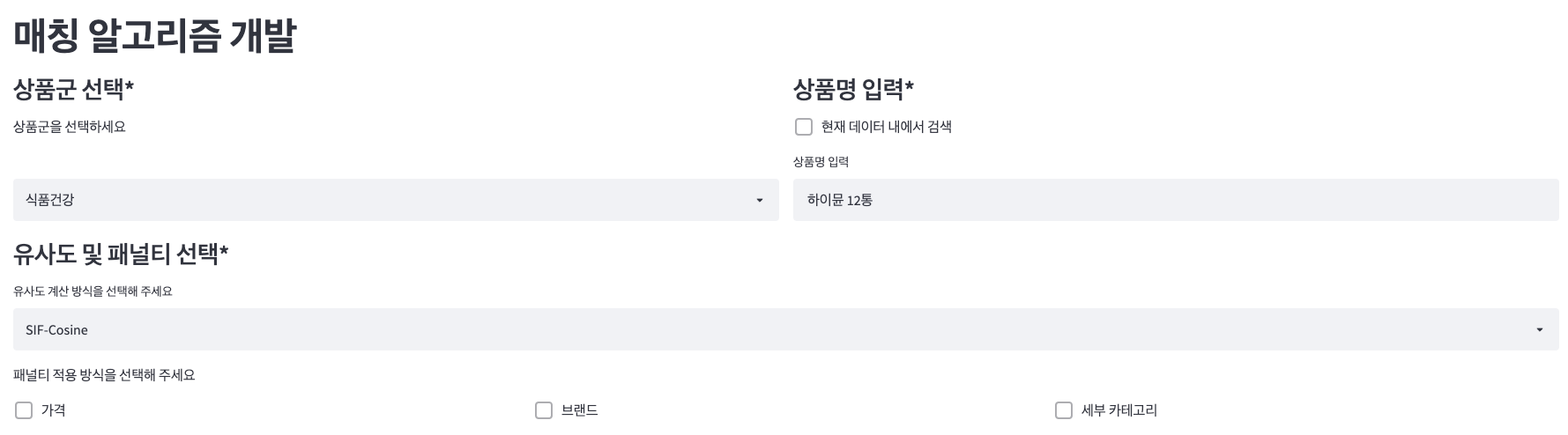
알고리즘을 통해 도출된 매칭 결과를 확인해 볼 수 있는 웹 어플리케이션도 개발하였습니다. (Streamlit)
데이터 내 저장된 상품명 선택 및 키워드 직접 입력을 통해 매칭 된 동일 상품과 유사한 상품을 확인할 수 있습니다.
Streamlit은 Django와 같은 Python 웹 프레임워크로서
기계학습과 데이터 과학을 위한 맞춤형 웹을 만들 수 있는 오픈 소스 Python 라이브러리입니다.

향후 계획
이렇게 만들어진 결과를 어디에 적용하고, 어떻게 활용할 건지?
타 플랫폼(채널) 상품 정보들을 확인할 수 있는 대시보드에 매칭 결과를 추가 기능으로 제공하여,
타 플랫폼(채널) 상품의 정보와 방송 일정들을 편리하게 확인할 수 있도록 하는 것을 고려하고 있습니다.
타 플랫폼(채널)이 주는 영향을 파악하여 판매의 호부진 사유 분석 및 판매 전략을 세우는 것에 활용하는 것을 고민하고 있습니다.
마치며
프로젝트를 진행하면서 느낀 점은? 아쉬운 점이 있다면?
활용한 데이터 측면에서... 상품명뿐만 아니라 상품 상세 정보/이미지, 썸네일 이미지 (대표 이미지) 등도 고려하고자 하였으나,
여러 가지 여건들을 고려하여 우선은 상품명 중심으로 해당 알고리즘을 개발하는 방향으로 프로젝트의 범위를 조정하였습니다.
(상품 상세 이미지 내 텍스트 OCR 처리, 학습을 위한 상품 이미지의 충분한 적재기간, 프로젝트 진행 기간 및 상황 등)
개발된 알고리즘 측면에서... 활용하고 학습할 수 있는 데이터에는 한계가 있었고, 여러 가지 상황들을 고려하여야 했습니다.
상품 매칭과 관련하여 여러 논문에서 제안하고 개발한 알고리즘을 구현하고 또 업그레이드시키고 싶은 소망도 있었습니다.
하지만 정해진 내간 내 결과를 도출해야 하며, 공수 대비 효율도 고려하여야 했으므로 여건 내에서 최선을 다하였습니다.
해당 알고리즘에 대한 사용자의 니즈와 유관 프로젝트 담당자들의 생각을 정확히 모르는 상태에서,
공수가 많이 들어가는 시행착오를 해볼 수 없었지만 만족스러운 결과물로 인해 "Simple is Best"라는 교훈도 얻는 수 있었습니다.
속도와 적시성이 중요한 현장에서 알고리즘의 복잡성과 최신 기술 등은 상황에 따라 분석가의 욕심이 될 수 있다는 생각도 하였습니다.
분석적으로 부족하다고 생각할 수 있겠지만 현장의 수많은 상황 속에서 타협하고 조율하는 것도 쉽지 않았다는 말씀을 드리고 싶습니다.
'Data&AI' 카테고리의 다른 글
| LLM을 활용한 AI 와인 라벨 이미지 검색 개발 여정 (3) | 2025.07.14 |
|---|---|
| 쇼핑에 영상을 더하다: GSSHOP 숏픽 추천 알고리즘 진화기 (0) | 2025.04.03 |
| 실시간 추천을 위한 kubeflow 환경 구축 (2) | 2022.01.04 |
| Language Model을 활용한 상품평 감성분석 (3) | 2021.12.29 |
| End-2-End AI Product 개발하기 (1) | 2021.11.26 |