
안녕하세요, 최근 검색추천팀 플랫폼파트에서 새로 개발하여 우리동네GS 앱의 와인25플러스에서 출시한 서비스인 AI 와인 이미지 라벨 검색 기능에 대한 설명과 성능 개선 과정 내용을 공유드리고자 합니다.
이에 앞서 와인25플러스 서비스와 AI 와인 라벨 이미지 검색 서비스가 만들어지게 된 배경을 소개하겠습니다.
🍷 우리동네GS - 와인25플러스란?

전국 곳곳에 분포한 GS25(편의점)와 GS더프레시(마트)에서는 1만여 종의 다양한 주류들을 취급하여 집근처 어디서나 쉽게 접할 수 있습니다. 오프라인 지점의 매출 유도와 온라인으로도 편한 서비스 제공을 위해, 우리동네GS(이하 우동지) 앱에서는 "와인25플러스"를 통해 와인, 양주, 수제맥주 등 다양한 주류를 언제 어디서나 GS25 및 GS더프레시에서 예약/픽업으로 이용할 수 있는 주류 특화 서비스를 제공하고 있습니다.

특히 와인25플러스에서는 위에서 보시다시피 주류에 대한 전문지식이 없는 고객도 이애할 수 있도록 위의 앱 화면과 같이 품종, 당도, 산미, 수상 이력, 페어링 정보 등을 함께 제공하고 있는데요.

오프라인 매장에서도 고객의 니즈를 잘 이해하고 직접 손으로 주류 라벨을 해석하여 추천 문구를 써 붙이는 등 다양한 따뜻한 방식으로 고객을 응대하고 계십니다. 좀 더 익숙치 않은 와인과 주류에 깃든 이야기를 고객에게 더 쉽게 전하려는 정성이 느껴지는 부분인데요, 하지만 현실은 언제나 쉽지많은 않습니다. 와인 라벨의 경우 프랑스어/라틴어로 쓰여져 있어 일반 고객은 물론 점포 직원도 해석하기 어려운 경우가 많고 온라인에 검색 가능한 정보가 제한적일 때도 있을 뿐더러, 매장 직원 입장에서도 수천 개의 주류 상품 정보를 모두 기억하거나 일일이 설명해주는 건 물리적으로도 불가능합니다.
이러한 문제를 해결하기 위해 아래와 같은 서비스를 고안하게 되었습니다.
고객이 스스로 라벨 이미지를 기반으로 검색할 수 있는,
AI 와인 이미지 라벨 검색 서비스

이 서비스는 우동지 앱의 와인25플러스 화면에서 고객이 와인의 병을 촬영하면 AI가 라벨의 텍스트와 색상, 병 모양을 인식하여 가장 유사한 상품들을 검색하여 찾아줍니다. 검색 결과에서 원하는 와인을 클릭하면 자세한 상품 정보로 바로 이동할 수 있어 고객은 손쉽게, 그리고 경영주님의 응대는 더 쉬워집니다.
그럼 이제부터 본격적인 기술 이야기를 시작하겠습니다.
🤖 LLM(Extract OCR) + Multi Modal Search(Embedding Image + Text)
상품 이미지에서 텍스트를 추출하거나 이미지 자체를 Embedding Model을 활용하여 검색하는 기술 등 많은 방법들과 사례가 존재합니다.
하지만 와인25 플러스에서 취급하는 상품들은 와인, 위스키, 맥주 등 다양한 종류와 국내를 비롯한 해외의 상품들이 대다수인 도메인 특성을 고려해야 합니다.
우선 여러 실험 과정을 진행하였는데, 텍스트를 추출하는 OCR 기술만 활용하였을 때에는 어떤 언어인지 파악하기 어려워 난해한 언어로 추출되기도 하였고요, 단순히 이미지만 가지고 파악하였을 경우에는 병의 모양이 비슷하면 대부분 유사한 상품이라고 검색이 되거나 비슷한 에디션의 상품들이 많아 텍스트의 부가 정보를 필요로 함을 깨달았습니다.
그리고 마지막으로 OCR 기술은 ML기반의 전통적인 다른 방식보다는 Amazon Bedrock의 Foundation Model(Antropic Claude 3 Haiku)을 활용하여 LLM을 통해 주류 라벨 내의 텍스트를 추출하는 것이 성능이 더 뛰어나, 해당 방식을 채택하였으며 흐름도를 간단하게 도식화하면 다음과 같습니다.
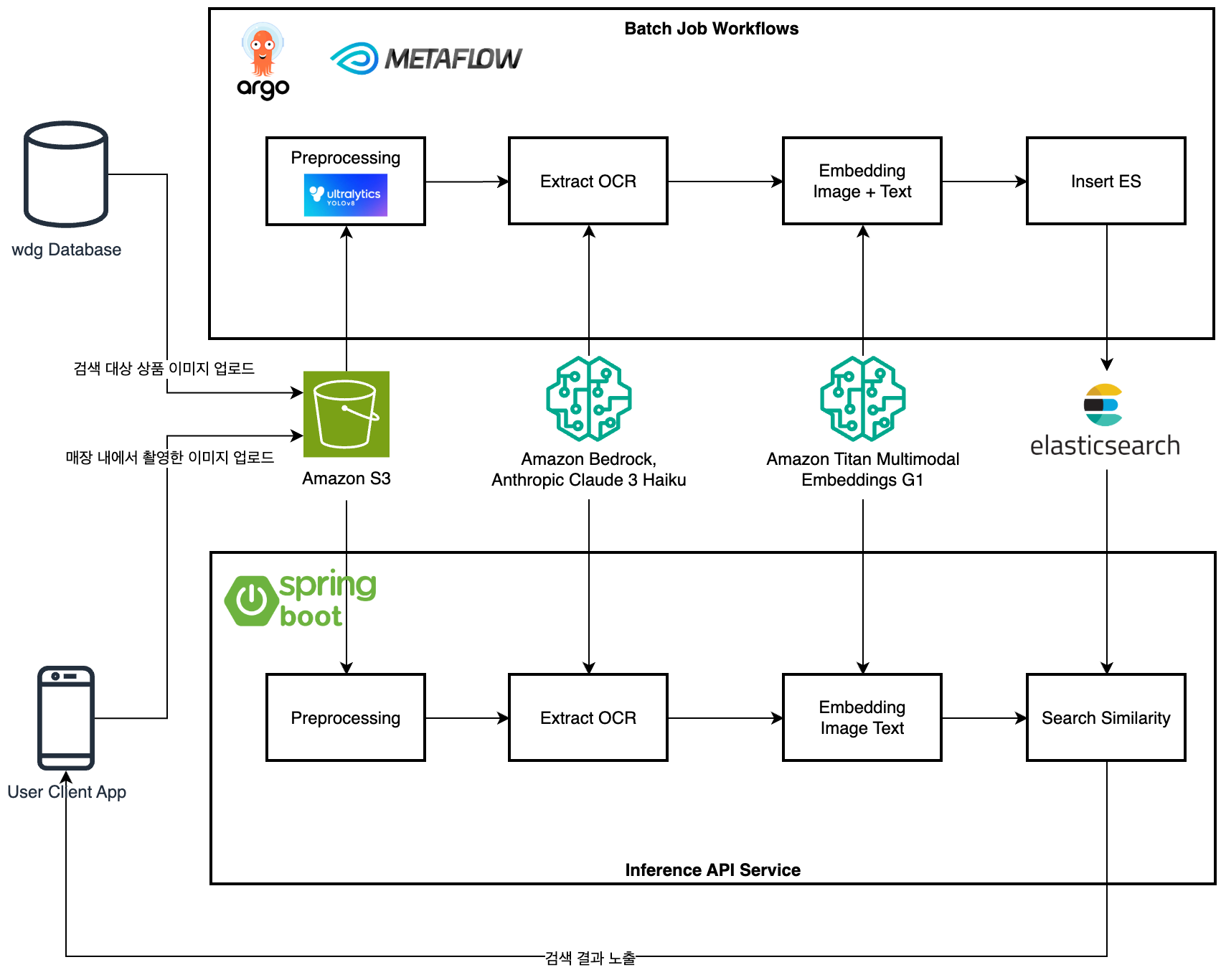
전체적으로 크게 상단에는 배치 작업을 통해 검색 대상 상품의 이미지를 분석하여 Vector DB를 만드는 과정이며, 하단에는 사용자가 이미지를 촬영하여 유사한 상품을 찾는 검색 과정으로 나눕니다. 배치 작업과 추론 작업 모두 거의 같은 로직으로 AWS 클라우드의 리소스를 활용하고 Elasticsearch를 Vector DB로 사용하여 이미지를 분석하고 벡터화의 과정을 거치지만, 약간의 미세한 로직 차이가 있습니다.
우선 검색이 가능하기 위해서 상단에 위치한 배치 작업을 위주로 설명드리겠습니다.
Batch Job Workflows
우동지의 데이터베이스에 온라인으로 등록된 주류들을 매 시간마다 수집하여 Vector DB에 존재하지 않은 상품이 있을 경우, 이미지를 분석하여 Vector를 저장하는 파이프라인을 실행합니다. 검색추천팀 플랫폼파트에서 운영하고 있는 Kubernetes의 Argo Workflows기반으로 배치 작업이 실행되며 Metaflow를 통해 쉽게 실험, 관리하고 모니터링이 가능합니다.

이제는 좀 더 상세한 배치 작업 파이프라인의 컴포넌트에 대한 설명입니다.
1. Preprocessing: 전처리 구간
상품 정보에 등록된 주류 이미지의 사이즈를 resizing하는 등 전처리하는 구간입니다. 하지만 상품 이미지를 보면 아래와 같이 주류만 찍힌 이미지가 아니라 박스와 포장버전? 등의 노이즈가 많아 검색 기능에 방해가 될 수 있습니다. 이를 위해 YOLOv8 모델을 통해 병이라고 인식되는 위치만 탐지하여 이미지를 자르도록 설정 후 Amazon S3에 저장합니다. 이러한 객체 탐지 과정은 배치 작업에서만 수행되며 추론 작업에서는 진행하지 않습니다.

2. Extract OCR: LLM을 통해 이미지 내 텍스트 추출하는 구간
위에서 병 모양만 자른 이미지를 불러왔다면, 이제는 Amazon Bedrock Claude-3-Haiku(anthropic.claude-3-haiku-20240307-v1:0) 모델 API를 활용하여 주류 라벨에서 상품명, 브랜드, 품종 등 텍스트 정보를 추출하라는 프롬프트와 이미지 정보를 송신합니다.
LLM 모델은 텍스트 추출할 대상을 이미지 내에 분석하여 결과를 JSON 형식으로 반환하는 것이 미션인데요, 많은 실험을 통해 프롬프트 명령에는 단순히 텍스트 정보 추출 대상 뿐만 아니라 추론의 품질을 높이기 위해 Hallucination을 방지하고 유효성을 검증하기 위한 내용과, 예시를 포함한 Few shot을 추가하였습니다.
1. 구조화된 정보를 추출
- itemName: 상품명 (완전히 보이는 경우만)
- brand: 브랜드명 (완전히 보이는 경우만)
- breedSpName: 포도 품종 (주류의 타입이 와인의 경우)
- isProduct: 주류 제품 여부
2. 엄격한 추출 규칙
- 추측 금지: 완전히 보이는 텍스트만 추출
- 부분 텍스트 무시: 잘린 단어나 부분적 정보는 무시
- 정확성 우선: 확실하지 않으면 빈 문자열 반환
3. 제품 유효성 검증
- 음료 제품만: 와인, 위스키, 맥주 등 액체 음료 컨테이너
- 의류/전자제품 제외: 바지, 신발, 전화기 등은 제외
+ (Few shot 및 기타 추가 조건 등 이하 생략)
3. Embedding Image + Text: Multi Modal Vector 생성하는 구간
주류 제품이 맞다면 이제 상품명, 브랜드명, 포도 품종 등 텍스트 정보들을 알 수 있습니다. 이미지 정보를 Vector로 구성할 때 텍스트 정보들도 함께 포함하는 Multi Modal 방식으로 Embedding을 합니다. Amazon Bedrock Titan Image(amazon.titan-embed-image-v1) 모델을 사용한다면 이미지와 텍스트 정보를 결합하여 Embedding 작업을 거쳐 총 1024개의 길이를 가진 Vector를 반환합니다.
4. Insert ES(Elasticsearch): Vector DB 저장
최종적으로 이미지와 텍스트 정보들이 담긴 Vector를 DB에 저장하여 Cosine Similarity를 계산하여 Score를 산출할 수 있도록 Elasticsearch 검색 엔진에 Bulk로 적재 및 인덱싱 처리를 합니다. 인덱싱이 완료 후 불과 몇 초 내에 검색이 가능한 상태로 변경됩니다.
Inference API Service
이미 앞서서도 언급하였지만 추론 작업도 배치 작업과 상당히 유사한 로직입니다. 약간의 차이가 있다면 데이터 출처, 데이터 전처리 방식과 마지막 최종 작업의 미션입니다. 우선 데이터는 우동지 데이터베이스에서 수집하는 것이 아닌, 우동지 앱(Flutter)에서 사용자가 촬영한 이미지를 Amazon S3에 저장하고 이 위치에 접근하여 검색 API 서버가 데이터를 다운 받는 것 부터 추론 작업의 시작이 진행됩니다.
1. Preprocessing: 전처리 구간
Amzon S3로 부터 이미지 다운 후 이미지 전처리를 이전 배치 작업과 동일하게 작업하되, YOLO를 통한 객체 탐지는 진행되지 않습니다.
2~3. Extract OCR / Embedding Image + Text
배치 작업과 동일한 프롬프트, Embedding 방식은 동일하게 적용됩니다.
4. Search Similarity
API 서버에서 이전 단계로 부터 얻은 1024개의 Vector 값을 Elasticsearch에 Cosine Similarity Score를 요청합니다. Elasticsearch 검색 엔진을 통해 가장 유사한 Vector를 가진 상품들이 무엇인지 빠른 시간 내에 결과값을 받을 수 있으며, 유사한 점수가 0.73 이상인 상품만 결과를 사용자의 화면에 노출할 수 있도록 응답을 보냅니다. 만약 아무런 상품도 0.73보다 높지 않다면 검색 신뢰도를 높이기 위해 아무런 상품을 찾지 못하였다고 화면이 노출됩니다.
🔧 검색 결과 개선을 위한 튜닝
서비스 오픈 전까지 많은 실험와 자체적인 테스트로 개선을 할 만할 점들을 찾아 품질을 높이는 시도들을 여럿 진행했습니다. 검색 결과의 품질을 높인다는 것은 타 AI 모델과 같이 Metrics를 높이는 정량적인 성격보다는, 단순한 기술적인 요소 뿐만 아니라 도메인을 고려하는 등 사람이 느끼는 정성적인 성격의 검색 결과 품질 개선을 더 중요시 하기도 합니다. 그래서 다음과 같은 4가지의 시도와 개선으로 검색 결과를 개선하였습니다.
1. 상품 데이터 품질 높이기
우동지 데이터베이스에 저장되어 있는 상품 정보 중 일부 이미지는 저화질로 저장되어 있어 텍스트 추출이 잘 되지 않아 Vector로 변환 후 실제 사용자의 스마트폰으로 촬영한 고화질의 데이터와 비교하면 유사도 결과가 잘 나오지 않는 문제가 있었습니다. 이를 개선하기 위해 현업으로 부터 고화질의 데이터를 받아 데이터의 품질을 높일 수 있었습니다.
전처리 방식도 고화질의 데이터인 경우 resizing을 진행하지 않고 그대로 LLM을 통해 OCR 추출을 하여 더 정밀한 결과를 얻을 수 있었습니다. 또한 Embedding 구간에서는 Multi Modal 방식으로 이미지와 텍스트를 함께 결합하는 방식이 아니라 텍스트만 Embedding하여 검색하는 방식이 더 유사한 상품을 찾아낸다는 성능을 보였습니다.
2. 비영어권의 상품 취급
Amazon Bedrock Haiku 모델을 통한 OCR 추론은 영어로 라벨링된 상품인 경우는 잘 추출되지만 아시아권 주류의 경우에는 텍스트가 추출이 잘 되지 않은 점이 발생하고 한자의 필체가 다양하다 못해 그림처럼 그려진 상품들이 많아서 인식률이 현저히 떨어졌기 때문에 분기 처리를 추가하여 전처리를 비롯한 Embedding 방식까지 다른 방법으로 고려해 보았습니다.
LLM을 통해 OCR을 추론할 때에 언어를 감지하여 만약 영어로 구성되어 있다면 기존 로직을 유지하고 그렇지 않은 다른 언어라면 텍스트 추출 결과는 무시하고, Amazon Bedrock Titan Image 모델이 아닌 Hugging Face에서 제공하는 SigLIP 모델을 활용해 이미지 정보만 Embedding하는 방식을 적용하는 것입니다. 인식이 잘 안되어 이상한 텍스트가 추출되어진 더미 데이터를 차라리 Multi Modal에 넣지 않는 것이 더 좋은 결과를 보였으며, Embedding 모델 또한 여러 실험을 통해 영어권이 아닌 경우 Amazon Bedrock Titan Image 모델보다 SigLIP 모델이 의미 있는 Vector를 생성한 결과를 보였습니다. 따라서 최종적인 흐름도는 다음과 같이 구성되어 현재 운영중입니다.

3. 주류 도메인을 좀 더 고려하기
위스키나 와인의 경우 년도가 다르면 차이가 (매우매우)많이 난다는 빈티지의 특성이 존재하기 때문에 현업에서는 아예 다른 상품으로 취급합니다.
이를 반영하기 위해 LLM에 OCR을 추출할 때 프롬프트에다가 라벨에 년도가 포함되어 있다면 추출하도록 수정, 그리고 해당 정보도 또한 Multi Modal을 통해 Embedding 할 때 텍스트 정보에 추가하도록 하였습니다. 이를 통해 동일한 주류이더라도 좀 더 정확한 년도 정보까지 고려하여 검색을 진행할 수 있습니다.
4. Cross-Region Inference 설정하기
만약 너무 서비스가 흥해서! 요청 처리량이 많아 갑작스런 장애에 대비하기 위해 API 서버에 HPA(Horizontal Pod Autoscaling)를 적용하였지만, 문제는 처리 지연량이 높아진다면 사실 가장 큰 지연이 될 위치로 추정하기로 Amazon Bedrock의 API 서비스가 원인일 수 있습니다.
us-east-1의 Region에서 Haiku 모델에 요청이 갑작스럽게 많아져서 Fallback으로 us-east-2 Region의 Haiku 모델에 추론을 하는 방식으로 API의 서버에서 (수제)코드로 방어 로직을 만들었는데, 사실 아주 적은 노력과 안정성으로 대안이 가능하였습니다. 바로 Amazon Bedrock API 호출 시에 들어갈 입력 변수에 모델 명만 수정하면 더 AWS가 내부적으로 알아서 Fallback 로직으로 Cross-Region Inference를 지원하는 내용이며, 단순히 API를 사용할 때 모델의 이름을 다음과 같이 설정하면 별도로 방어 로직을 만들 필요가 없습니다.
As-is : “anthropic.claude-3-haiku-20240307-v1:0”
To-be : “us.anthropic.claude-3-haiku-20240307-v1:0”
✅ 최종 테스트 결과 및 회고
어느 정도 개선이 되었다 판단하고 서비스 오픈 전, 얼마나 검색 성능이 나오는지 팀 자체적으로 테스트 가설 수립과 진행을 하였습니다. 편의점이나 마트에서 에서 진열된 와인의 경우 여러 방법을 통해 검색을 할 것이라고 판단하에 2개 촬영 방식의 케이스를 나누어 테스트를 진행하였으며, 와인을 직접 꺼내서 촬영하는 방식으로 첫 번째, 너무 무겁거나 깨질까봐 부담이 되서? 혹은 귀찮아서? 어쨌든 그냥 진열된 상태로 촬영하는 두번째 케이스로 나누었습니다. 일부 매장의 상단 진열대에 거치된 와인은 매우 높아서 꺼내기가 힘들 때도 있으니까요.

테스트 대상은 165개의 주류 상품을 테스트하였으며, 진행 결과 70%의 검색 성공률을 보였습니다. 예상보다 낮은 성공률을 기록하였는데, 실제 검색 실패의 유형을 분석한 결과 대부분은 온라인에서 취급하지 않고 오프라인에서만 판매하는 상품이다 보니 Vector DB에 존재하지 않은 케이스가 대부분이었습니다. 이를 고려한다면 온라인 취급 상품에서는 상당히 높은 검색의 성능 결과를 보입니다.
또한 의외로 검색 성능이 보인 경우도 있었는데요, 바로 진열대에 그대로 촬영하였을 때 진열대 안전 바 때문에 라벨이 일부 가려져서 잘 안보이는 문제가 있는데에도 검색이 잘 된다는 점입니다. 아무래도 이미지를 얼마나 유사한지 판단하겠지만 일부 텍스트 정보들을 함께 모아 유사한 상품을 찾기 때문에 더 풍부한 검색의 힌트를 모델이 얻어서 그런 것이 아닌가 싶습니다. 이는 타사 기술과 비교하였을 때 안전 바에 가려진 주류를 촬영하였을 때 보다 뛰어난 검색 결과를 보였습니다.

회고

와인을 비롯한 주류의 라벨 이미지를 통해 유사한 상품을 찾는 검색 기능을 구현하기에는 예전과는 달리 단순한 이미지의 정보만 판단하는 것이 아닌, LLM을 활용한다면 텍스트를 추출하여 Multi Modal로 더 풍부한 정보를 결합하여 검색 성능이 향상된다는 교훈을 받았습니다.
이처럼 LLM을 활용한 사례는 더 확장될 것으로 보이며, 향후 완벽하진 않지만 Silver Bullet 도구가 될 수도 있겠다는 생각이 들었습니다.
이번 개발한 AI 이미지 라벨 검색 기능은 향후 고도화할 부분이 아직 많습니다. 가장 시급한 문제는 온/오프라인에서 취급하는 상품의 Sync를 맞출 필요가 있으며, 검색 실패의 경우를 분석하여 최적의 유사도 Threshold를 조정해야 합니다.
마지막으로 70%의 검색 성공률을 보였다는 뜻은 30%의 검색 실패율을 가지기도 합니다. 하지만 항상 검색 실패라는 뜻은 부정적인 의미를 갖기도 하지만, 다르게 생각하면 간접적으로 고객이 원하는 상품이라는 것으로 해석될 수 있어, 검색 실패가 높은 상품들을 경영주 분들에게 발주 상품 추천으로 이어질 수 있다는 아이디어로 확장할 수 있을 것으로 보입니다.
긴 글 읽어주셔서 감사합니다:)

박동우 Ryan | DX본부 플랫폼DX부문 O4O DX팀 검색추천파트(P)
추천 서비스 개발과 MLOps 플랫폼 운영 담당하고 있습니다.
0에서 100까지의 모든 AI 기술 개발을 좋아하며
눈에 띄진 않지만 세상을 바꾸는 기술을 만들고 싶습니다.
'Data&AI' 카테고리의 다른 글
| 쇼핑에 영상을 더하다: Part 2. 영상을 '이해'하기 시작하다 (0) | 2026.03.30 |
|---|---|
| 비개발자 리서처가 AI로 인터뷰를 자동화하기까지: GS리테일 리서치봇 구축기 (0) | 2025.12.08 |
| 쇼핑에 영상을 더하다: GSSHOP 숏픽 추천 알고리즘 진화기 (0) | 2025.04.03 |
| 실시간 추천을 위한 kubeflow 환경 구축 (2) | 2022.01.04 |
| Language Model을 활용한 상품평 감성분석 (3) | 2021.12.29 |